Hi 
So let’s say we create a new table (which will eventually contain a million+ records):
CREATE TABLE duplicates (
id int(11) not null primary key auto_increment,
username varchar(256) not null,
time timestamp not null
);
INSERT INTO duplicates VALUES
(null, 'admin', '2018-08-02 12:30:40'),
(null, 'admin', '2018-08-03 11:20:40'),
(null, 'admin', '2018-09-02 00:30:40'),
(null, 'admin', '2018-09-02 12:30:40'),
(null, 'admin', '2018-10-02 12:30:40'),
(null, 'bill', '2018-08-02 12:30:40'),
(null, 'bill', '2018-08-03 11:20:40'),
(null, 'bill', '2018-09-02 00:30:40'),
(null, 'bill', '2018-09-02 12:30:40'),
(null, 'bill', '2018-10-02 12:30:40'),
(null, 'ryan', '2018-08-02 12:30:40'),
(null, 'ryan', '2018-08-03 11:20:40'),
(null, 'ryan', '2018-09-02 00:30:40'),
(null, 'ryan', '2018-09-02 12:30:40'),
(null, 'ryan', '2018-10-02 12:30:40');
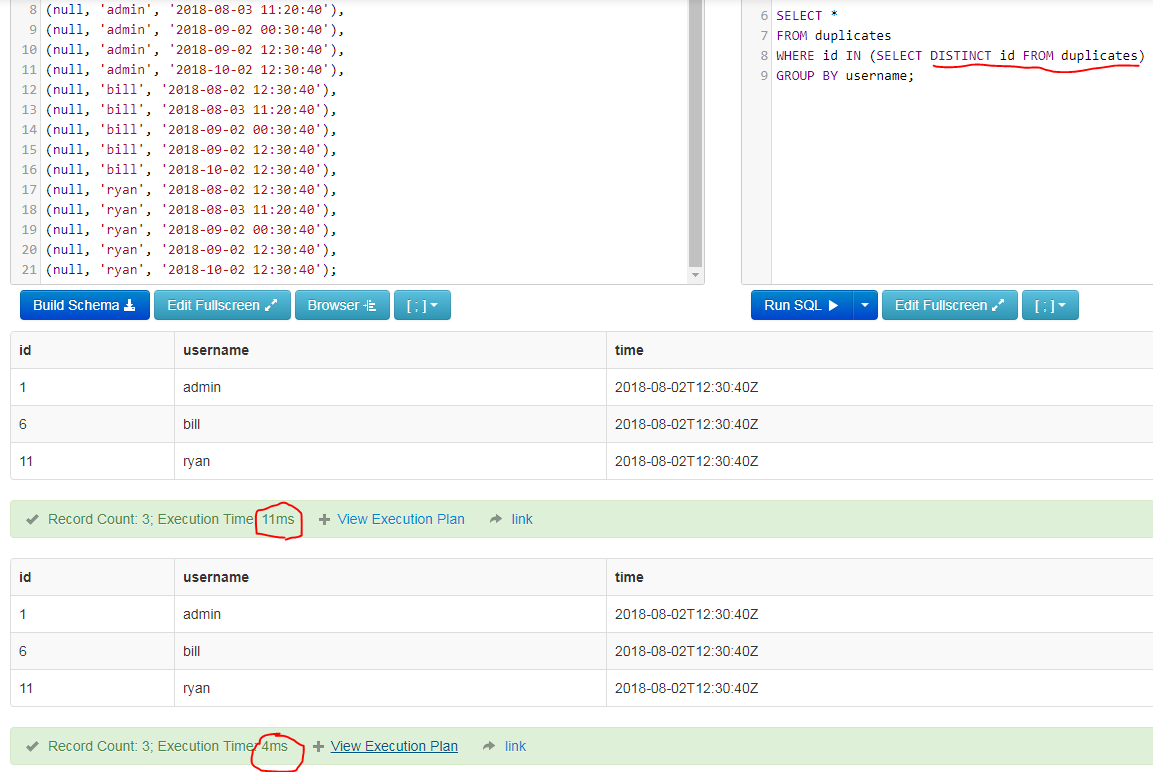
Then to query the latest distinct record, I am using one of the statements below.
So the question is, which of the two statements below should be used for this purpose?
SELECT *
FROM duplicates as t1
INNER JOIN (SELECT MAX(id) as id FROM duplicates GROUP BY username) as t2
ON t1.id = t2.id;
or:
SELECT *
FROM duplicates
WHERE id IN (SELECT MAX(id) FROM duplicates GROUP BY username);
The table might get up to a million+ rows, so speed & efficiency is necessary. After reading up a bit I assumed that the INNER JOIN was faster, but I have no explanation to back that assumption. Can anyone clarify this?